Exchange 2013 : la sécurité contre les pannes avec trois centres de données
En avril, Ross Smith IV a présenté la nouvelle architecture prioritaire d’Exchange 2013 à la Conférence Microsoft Exchange à Austin. Vous pouvez consulter l’enregistrement de la séance sur Channel 9. Au lieu ou en complément de cet enregistrement, vous pouvez également lire un article sur le blog de l’équipe d’Exchange. J’ai consacré le présent article à la présentation des avantages du nouveau design.
En avril, Ross Smith IV a présenté la nouvelle architecture prioritaire d’Exchange 2013 à la Conférence Microsoft Exchange à Austin. Vous pouvez consulter l’enregistrement de la séance sur Channel 9. Au lieu ou en complément de cet enregistrement, vous pouvez également lire un article sur le blog de l’équipe d’Exchange. J’ai consacré le présent article à la présentation des avantages du nouveau design.
Serveur de boîte de messagerie
Un composant important de cette architecture est bien entendu le Database Availability Group (DAG), qui peut contenir idéalement deux centres de données pour que la perte d’un site n’entrave pas l’accès aux e-mails. Dans le passé, le point épineux était l’emplacement du File Share Witnesses (FSW) avec les DAG disposant d’un nombre de nœuds pair, car celui-ci détermine le quorum entre les sites en cas d’interruption de réseau. Seuls les serveurs du DAG qui peuvent encore constituer le quorum peuvent mettre des bases de données à disposition. Le but de cette fonction est d’empêcher le syndrome Split-Brain, lequel signifie que deux copies d’une base de données sont actives simultanément et que le contenu diverge.
Malheureusement, en cas de perte d’un centre de données avec le File Share Witness, il est nécessaire d’intervenir manuellement pour forcer le quorum pour les nœuds restants du DAG. De nombreux administrateurs déplorent cet état de fait. Cependant, celui-ci s’explique facilement: un automatisme ne peut pas constater si le site qui aurait le quorum est vraiment tombé en panne ou si cela ne concerne que la connexion réseau. Dans ce dernier cas, il faut tout d’abord éteindre tous les serveurs de messagerie sur le site primaire avant de pouvoir basculer sur l’autre centre de données.
Avec Exchange 2013, Microsoft soutient (et, dans le cadre de l’architecture prioritaire, recommande) le déplacement du File Share Witness dans un troisième centre de données. Pour vous montrer les conditions et les configurations nécessaires, j’ai mis en place l’infrastructure nécessaire dans mon environnement de test. L’illustration suivante vous donne un aperçu des composants :
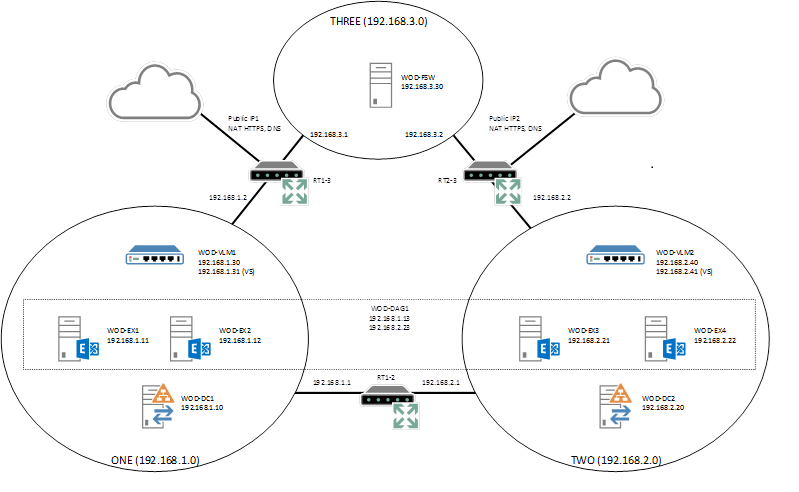
Comme vous pouvez le constater, l’environnement est composé d’un DAG avec quatre nœuds qui recouvre les sites AD ONE et TWO. Dans chacun des deux sites, il existe un contrôleur de domaine et un équilibreur de charge virtuel de la société Kemp. En tant qu’équilibreur de charge GEO, ce dernier est capable de distribuer les demandes des clients dans les deux sites. Le troisième site AD THREE ne contient qu’un seul serveur configuré comme témoin de partage de fichier. L’acheminement entre les sites est assuré par les routeurs basés sur Windows. Le point important ici est la nécessité de connexions redondantes entre les centres de données. Ce serait une mauvaise idée d’utiliser des VPN site-to-site sur un seul fournisseur ou sur MPLS, car toutes les connexions pourraient être concernées. Dans ce dernier cas, le quorum ne peut être constitué nulle part.
Quelques points à prendre en compte :
- Si le témoin de partage de fichier ne peut pas être configuré sur un serveur d’échange parce que seul des serveurs multirôles sont utilisés, le groupe Exchange Trusted Subsystem doit être membre du groupe d’administrateurs local sur le serveur, le rôle Serveur de fichier doit être installé et WMI doit être clairement autorisé par le pare-feu de Windows.
- Il existe un bug dans toutes les versions d’Exchange 2013, jusqu’à CU5 comprise. Ce bug place l’index des bases de données dans un état problématique, car le service responsable recherche un groupe AD inexistant. Il est préférable d’emblée de configurer le contournement dans l’article suivant : http://support.microsoft.com/kb%5C2807668/EN-US
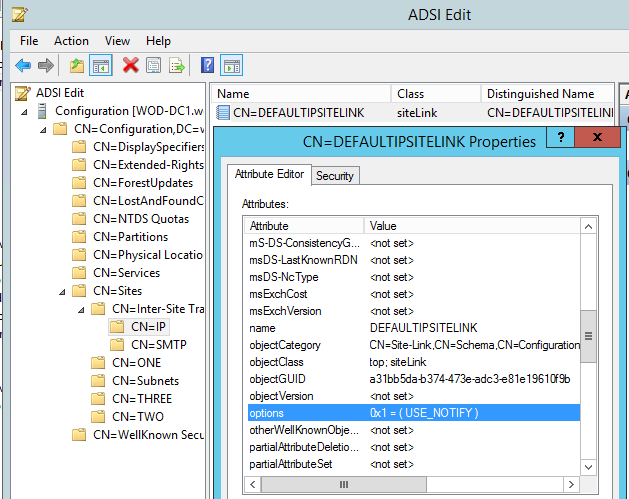
- Lors des modifications de la configuration d’Exchange, vous ne devriez pas oublier la durée de latence de la reproduction du répertoire actif, car la plupart des paramètres sont enregistrés dans la configuration de la partition. Le plus petit intervalle qui peut être configuré pour la réplication entre les sites AD est de 15 minutes. Cependant, il existe un autre moyen pour appliquer le même mécanisme comme pour la réplication à l’intérieur du site, ce qui réduit le temps de latence à seulement quelques secondes :

- Pour un environnement avec autant de copies de base de données comme dans mon exemple, Exchange Native Data Protection, JBOD devrait être pris en compte comme emplacement de stockage, ainsi que Continous Replication Circular Logging (CRCL).

Circular Logging ne doit être activé qu’après la création de plusieurs copies de la base de données. Le cas contraire, Jet circular logging sera utilisé au lieu de CRCL.
Le DAG à 4 nœuds de notre exemple ainsi que les 4 copies des bases de données permettent de couvrir les scénarios de panne suivants :
| Scénario | Résultat |
| Panne de max. 3 serveurs d’échange | Les bases de données sont activées sur un serveur restant. Tant qu’il n’y a pas simultanéité, Dynamic Quorum de Windows 2012 R2 autorise plusieurs pannes. |
| Panne d’un site | Les bases de données sont activées sur le site restant. |
| Panne de max. 2 connexions entre les sites (isolement d’un site) ou d’un accès public | Les sites restants conservent le quorum. |
| Panne du témoin de partage de fichier | Le FSW n’est nécessaire que lorsque le quorum doit être constitué. |
Client Access
Dans les précédentes versions d’Exchange, la communication avait lieu entre le rôle Client Access et le rôle Mailbox par l’intermédiaire de RPC, un protocole que la latence de réseau perturbe particulièrement. C’est pourquoi on a renoncé autant que possible à autoriser ce genre de trafic par connexions WAN. Par exemple, lors de l’accès à une boîte de messagerie en Europe par l’intermédiaire d’un centre de données américain CAS, un redirect qui relie tout d’abord le client avec un CAS européen a été renvoyé. Dans Exchange 2013, cela n’est plus nécessaire, car la communication entre CAS et MBX s’effectue à travers HTTP/HTTPS.
Exchange 2010 Exchange 2013
Ce changement s’accompagne également de la recommandation d’utiliser un nom unique et global pour l’accès. Pour cela, le FQDN de l’URL externe du répertoire OWA et ECP ne doit pas être réglé ou il doit alors être réglé de la même façon sur tous les sites, comme sur l’écran ci-dessous :
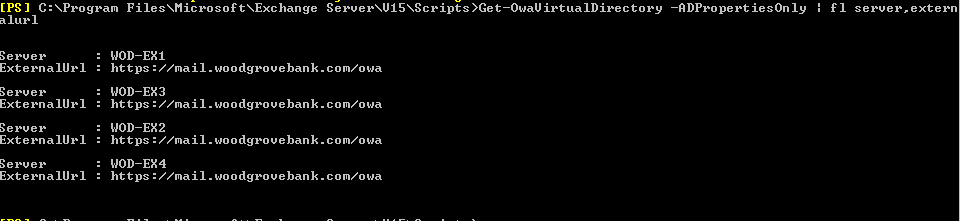
Pour que ce modèle fonctionne, le trafic ne doit pas être réparti dans un site avec l’équilibreur de charge, mais entre les sites. Pour cela, en théorie, il est possible d’utiliser DNS Round Robin. Cependant, il n’y a alors aucun contrôle d’état et le client essaie également d’atteindre le serveur/site qui n’est plus disponible. Le résultat est une durée de basculement plus longue qui ne correspond pas au délai de la première requête. Il est préférable d’utiliser un équilibreur de charge GEO, lequel n’est rien d’autre qu’un serveur DNS intelligent. En fonction du site du client et de l’état des serveurs, il renvoie d’autres adresses IP.
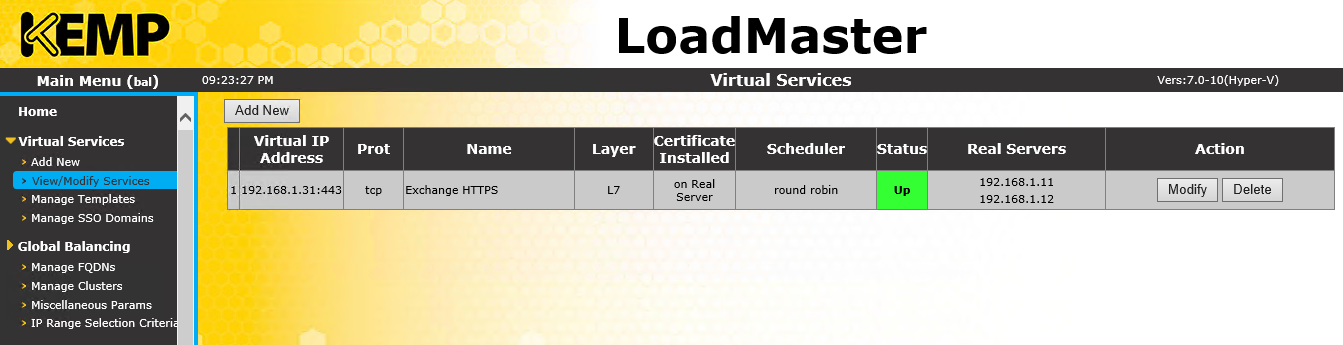
Les illustrations suivantes donnent un exemple de configuration dans Kemp Loadmaster :

Les adresses IP dans le réseau 10 sont celles accessibles par tous et renvoyées par le Loadmaster comme serveur DNS, tandis que les adresses 192 des IP virtuelles d’une grappe de serveurs correspondent sur un site.

La capture d’écran suivante affiche le service virtuel pour un site qui contient 2 serveurs backend.
Cette conception permet d’éviter les erreurs suivantes :
| Scénario | Résultat |
| Panne de max. 3 serveurs Exchange | Les équilibreurs de charge acheminent le trafic au(x) serveur(s) restant(s). |
| Panne d’un site | Les composantes d’équilibrage de charge GEO ne renvoient plus que l’adresse IP du centre de données en service. |
| Panne de max. 2 connexions entre les sites (isolement d’un site) ou d’un accès public | Les équilibreurs de charge acheminent le trafic au(x) serveur(s) restant(s). |
| Panne d’un équilibreur de charge | Les requêtes DNS sont automatiquement envoyées à l’équilibreur de charge restant grâce à plusieurs Name Server Records (NS). |
Résumé
La conception proposée par Microsoft est intéressante en raison de la haute disponibilité de l’infrastructure de messagerie, du basculement automatisé et de la simplicité de la configuration. Si vous souhaitez en savoir davantage, suivez un des cours suivants :