Ausfallsicherheit auf Standortebene für Exchange 2013
Serverausfälle passieren – leider. Umso wichtiger, dass man sich bewusst ist, was dabei passiert und wie solche Ausfälle abgefangen werden können. In diesem Tipp erklärt unser Kursleiter Markus Hengstler, welche Optionen für die Ausfallsicherheit von Exchange 2013 bezüglich ganzen Standorten bestehen.
In diesem Artikel werde ich Optionen für die Ausfallsicherheit von Exchange 2013 bezüglich ganzen Standorten beleuchten. Für die Auswahl der richtigen Lösung sind vorab einige Informationen nötig – es soll ja nicht so sein, dass einfach jene Option gewählt wird, die am besten in die bestehende Umgebung passt. Die Option soll in erster Linie den Anforderungen des Business entsprechen.
- Wie viele Standorte mit Exchange Servern sind vorhanden?
- Sind an allen Standorten Benutzer aktiv oder dienen einige nur dem Disaster Recovery?
- Welche Clients müssen von intern und extern zugreifen können: OutlookAnywhere, ActiveSync, Outlook Web App, POP3, IMAP?
- Welche Ausfallzeiten sind noch akzeptabel und wie viel Datenverlust darf maximal auftreten?
Für Exchange 2010 war noch die Frage wichtig, ob die Standorte auch in Active Directory als separate Site konfiguriert sind. Dies entfällt bei Exchange 2013, da Client Access Server nicht mehr als Array pro AD Site konfiguriert werden, sondern unabhängig in Loadbalancing Arrays unterteilt werden können.
Die Ausfallsicherheit in Exchange 2013 muss – wie auch schon beim Vorgänger – für alle Rollen geplant werden.
Mailbox-Server-Rolle
Für die Mailbox-Server-Rolle ist die Lösung ziemlich offensichtlich: Eine Database Availability Group (DAG) erzeugt Redundanz mit Hilfe mehrerer Datenbankkopien: Eine aktive und eine oder mehrere passive. Eine passive Kopie kann manuell (Switchover) oder automatisch (Failover) aktiviert werden, wobei sichergestellt sein muss, dass die vormals aktive Kopie nicht mehr zugänglich ist. Dies ist insbesondere bei standortübergreifenden DAG kritisch, da statt eines ganzen Serverraums auch nur die Netzwerkverbindung zwischen den Standorten ausfallen kann. Eine gleichzeitige Aktivierung von Kopien in beiden Standorten würde zu einem sogenannten Split-Brain führen: Inkonsistenz zwischen den Datenbanken.
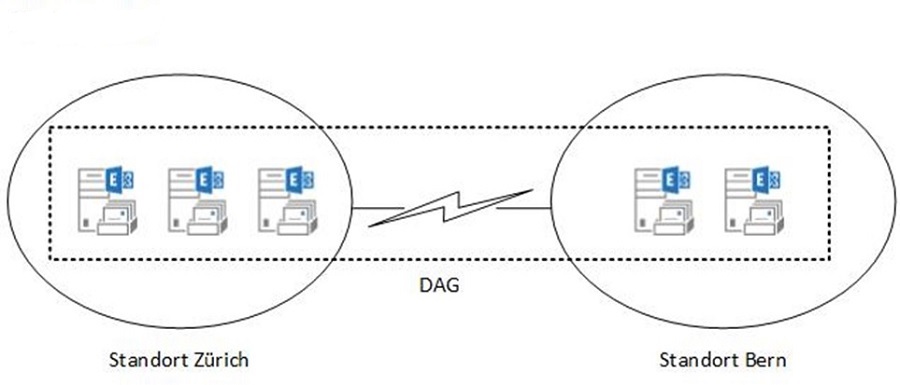
Bei einem standortübergreifenden DAG bestimmt das Quorum des Failover Clusters, welche Server bei Ausfällen die Datenbanken weiterhin gemountet haben dürfen. Hier ein Beispiel:
Ein 5-Node DAG ist über die zwei Standorte Zürich und Bern verteilt. Hier sehen wir den Status im Normalbetrieb:
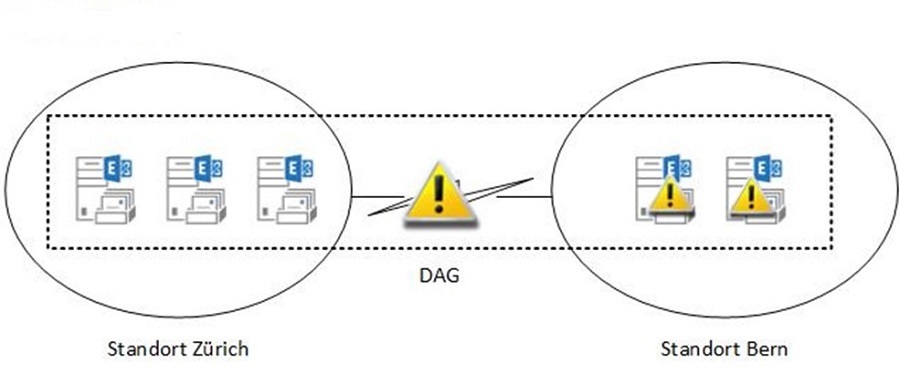
Fällt der WAN-Link nun aus, darf nur noch der Teil des DAGs weiterfunktionieren, der das Quorum hat – also die Mehrzahl der Stimmen (Votes). Im Beispiel mit ungerader Anzahl Nodes hat jeder Server eine Stimme. Die Server im Standort Zürich sehen noch 3 von 5 Stimmen, dürfen also die Datenbanken mounten. Wohingegen die Server im Standort Bern nur noch 2 von 5 Stimmen haben. Da dies nicht die Mehrheit ist, müssen sie alle Datenbanken dismounten.
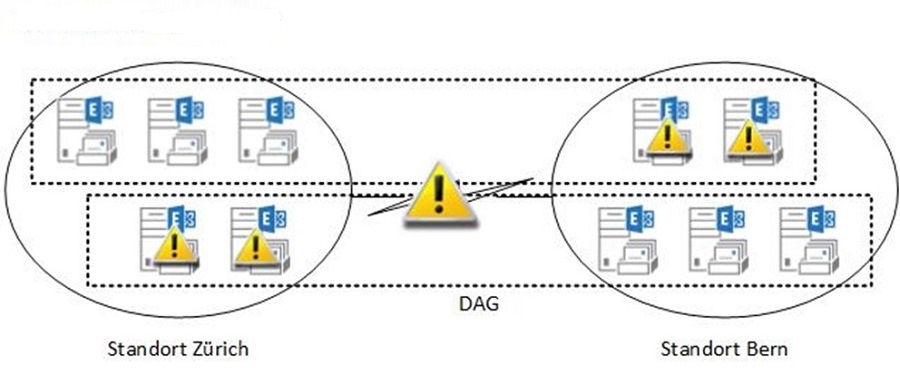
Sollen also aktive Benutzer in beiden Standorten ohne WAN-Link weiterarbeiten können, reicht dieses Design nicht aus. Es werden dann 2 DAGs benötigt.
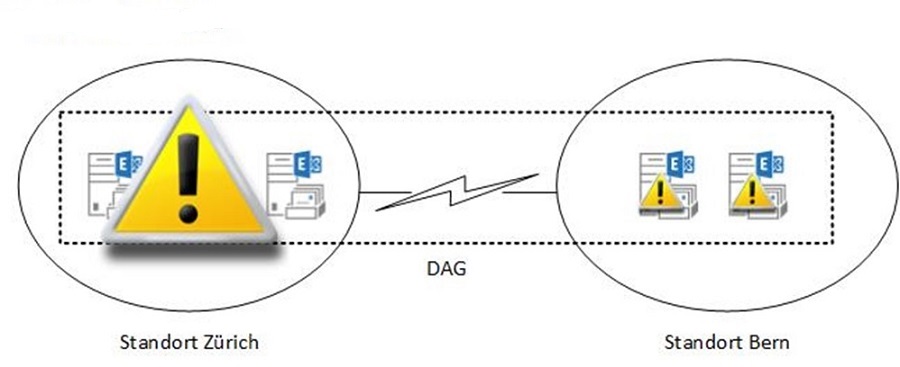
Fällt im Szenario mit einem DAG der Standort Zürich komplett aus, fahren wegen dem fehlenden Quorum in Bern die Server ebenfalls die Datenbanken herunter. Das Quorum muss dann manuell erzwungen werden.
Weitere Optionen:
Mit Windows Server 2012 wurde die Möglichkeit eines dynamischen Quorums eingeführt: Sollte im Beispiel «Ausfall WAN-Link» noch ein Server in Zürich ausfallen, würde der DAG – anders als ohne dieses Feature – immer noch weiterfunktionieren, da nach dem Wegfall der beiden Server in Bern das Quorum neu berechnet wird. Somit haben die beiden verbleibenden Server in Zürich noch 2 von 3 Stimmen statt 2 von 5.
Bei DAG mit gerader Anzahl Nodes muss noch eine zusätzliche Stimme geschaffen werden: der File Share Witness (FSW). Dabei handelt es sich um einen Windows File Share, auf den ein Cluster Node einen Lock hält und damit 2 statt nur eine Stimme hat. Somit muss für ein standortübergreifendes DAG-Design auch die Lokation des FSW berücksichtigt werden.
Ab Exchange 2013 wird auch unterstützt, dass sich der FSW an einem zusätzlichen Standort befindet.
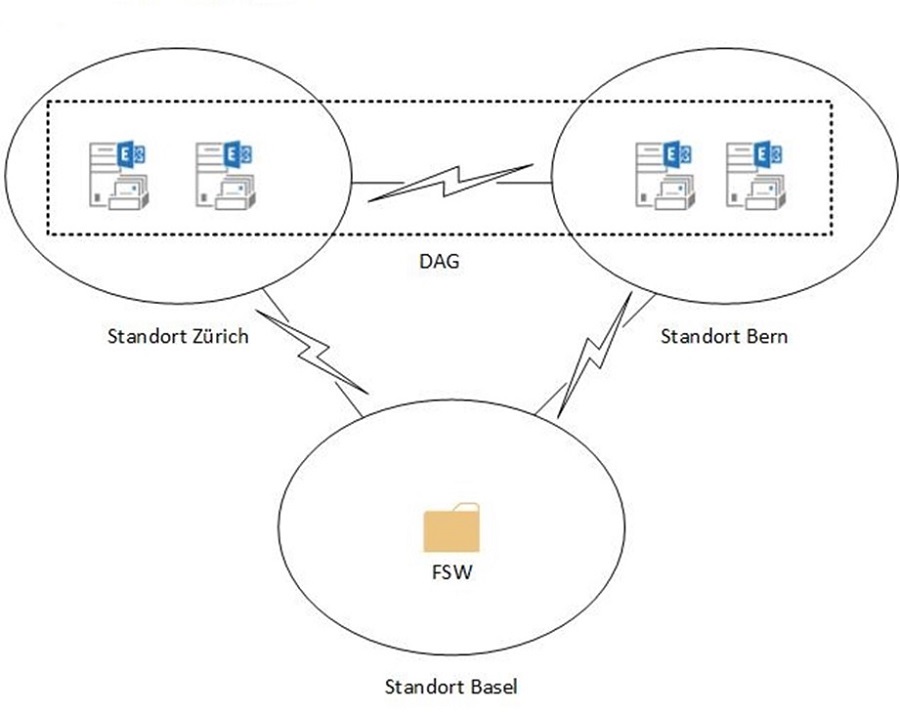
Vorteil dieser Lösung ist ein automatischer Failover, wenn ein Datacenter ausfällt.
Achtung: Die Anforderungen an die WAN-Links sind hoch. Diese müssen unabhängig voneinander sein, sonst kann ein Ausfall den kompletten DAG funktionsuntüchtig machen.
Client-Access-Server-Rolle
Für die Client-Access-Server-Rolle (CAS) muss Network Loadbalancing implementiert werden, damit die Lösung ausfallsicher wird. Bei Exchange 2010 wird sichergestellt, dass der Benutzer auf einen CAS im selben Standort zugreift, in dem sich auch seine Mailbox befindet, da die Verbindung zwischen CAS und Mailboxserver das latenzanfällige MAPI über RPC verwendet.
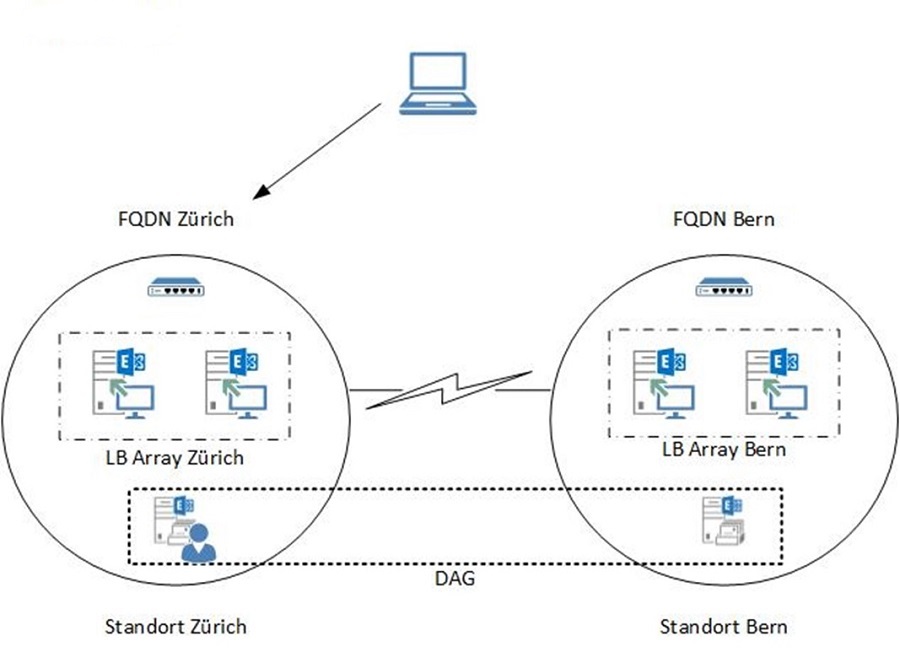
Bei Exchange 2013 ist der CAS nur ein Proxy, der die Verbindung mit dem gleichen Protokoll weitergibt, mit dem er es empfangen hat – also HTTPS. Damit ist es nun auch ohne Leistungseinbussen möglich, vom CAS aus den Mailboxserver in einem anderen Standort zu erreichen, was wiederum das Konzept des Client Access Arrays unnötig gemacht hat. Es ist aber immer noch möglich, standortbasierte FQDN zu verwenden, wie in diesem Beispiel:
Pro Standort ist ein Array von loadbalanced CAS Servern konfiguriert. Bei einem Ausfall wird die Mailbox über die Aktivierung des Datacenters Bern verschoben. Zusätzlich muss der FQDN des Standorts Zürich in DNS auf die IP-Adresse des Berner Arrays oder Reverse Proxy geändert werden.
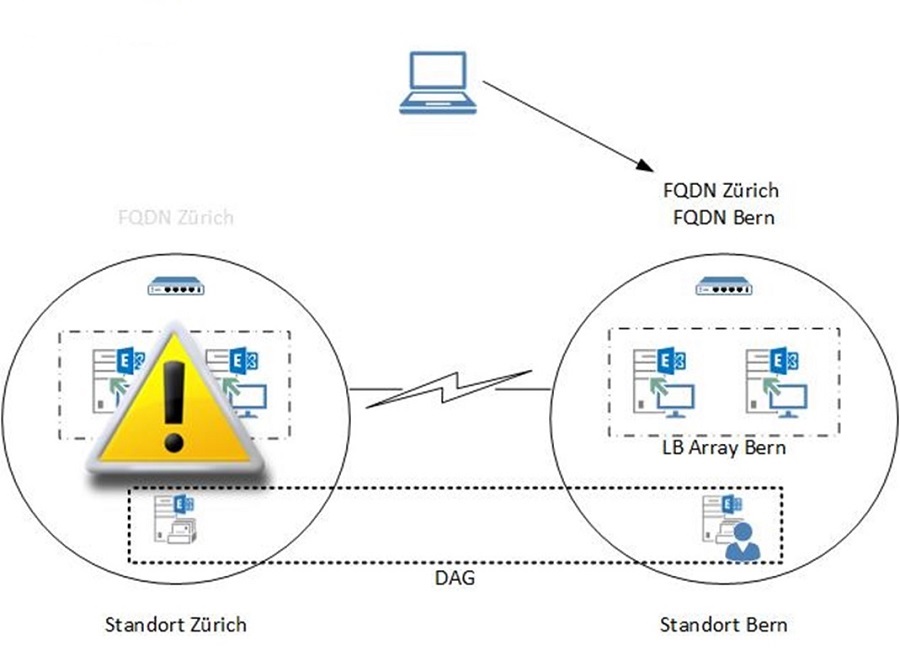
Es ist aber auch möglich, einen gemeinsamen FQDN für beide Standorte zu verwenden und per GEO-Loadbalancing auf die Standorte zu verteilen. Auch hier ein Beispiel:
Die Anfrage für den FQDN wird vom GEO-Loadbalancer (natürlich ebenfalls redundant ausgelegt) beantwortet. Der Client verbindet sich auf eines der beiden Arrays und wird gegebenenfalls zum Mailboxserver am anderen Standort weitergeleitet.
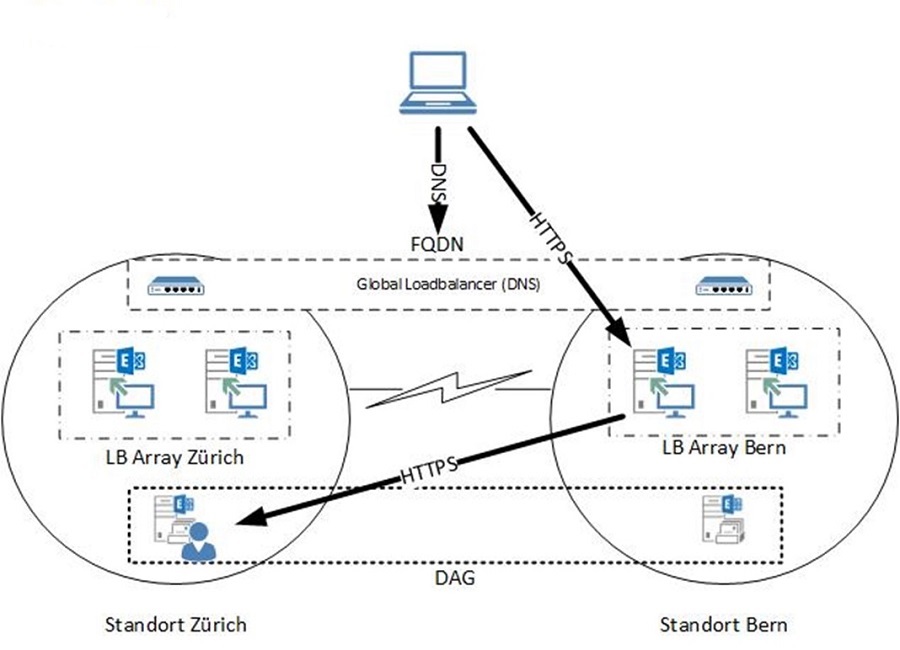
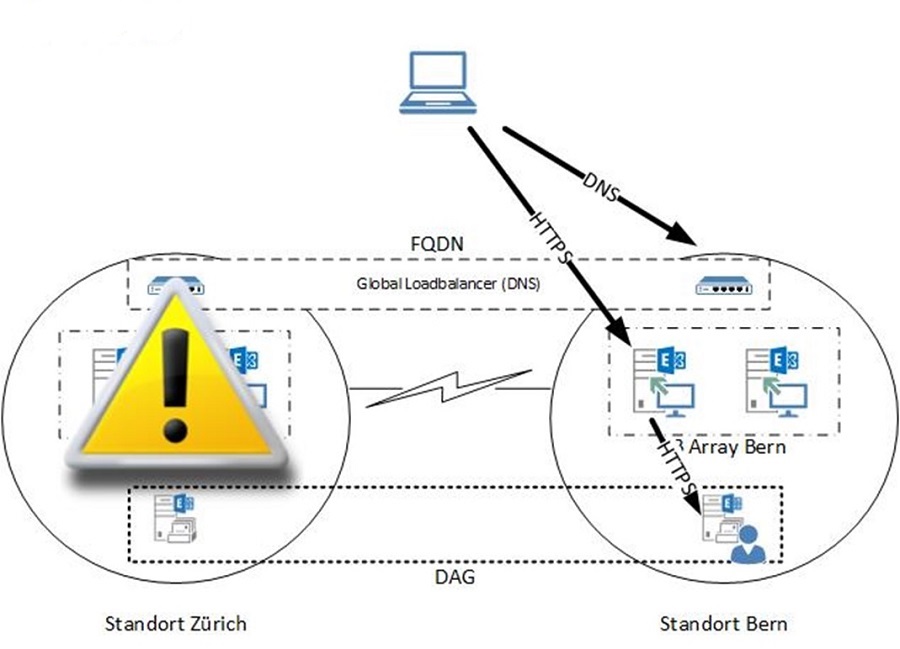
Theoretisch würde auch die Verwendung von DNS Round-Robin unterstützt – allerdings bietet diese Lösung keine Überwachung der Dienste und reagiert deswegen langsamer. Zudem lässt sich die Verteilung des Verkehrs auf die Standorte nicht steuern. Ein GEO-Loadbalancer hingegen bietet dazu mehrere Optionen.
Hub-Transport-Rolle
Anders als bei Exchange 2010 ist beim Nachfolger die Hub-Transport-Rolle auf CAS und Mailbox Server aufgeteilt. Die Funktion bleibt aber ebenso bestehen wie die Notwendigkeit einer Betrachtung bezüglich Verfügbarkeit für die folgenden Komponenten:
- SMTP-Dienst
SMTP kann über die gleiche Infrastruktur wie die CAS Server loadbalanced werden. Alternativ kann für externe Verbindungen auch eine Kombination von MX-Records in DNS verwendet werden, die entweder einen spezifischen Standort bevorzugen oder die Last über alle verteilt.
- E-Mails in Transit
E-Mails, die schon entgegengenommen, aber noch nicht in die Mailbox ausgeliefert wurden, werden zusätzlich in sogenannten Shadow Queues abgelegt, sodass immer zwei Kopien vorhanden sind. Neu wird in Exchange 2013 ein Server aus einem anderen Standort bevorzugt, sofern sich beide im selben DAG befinden. Ausserdem werden die E-Mails nach erfolgreicher Auslieferung nicht wie bis anhin aus der Shadow Queue gelöscht, sondern für einen definierten Zeitraum (Default: zwei Tage) in einer weiteren Datenbank, dem Safety Net, aufbewahrt.
Fazit
Exchange 2013 bietet für alle Rollen und Funktionen verschiedene Optionen, um auch Ausfälle ganzer Standorte abzufangen. Für weitere Informationen, wann welche Lösung sinnvoll ist oder wie sie konfiguriert werden, empfehle ich Ihnen folgende Kurse:
- Core Solutions of Microsoft Exchange Server 2013 («EX1»)
- Advanced Solutions of Microsoft Exchange Server 2013 («EY1»)