Die ultimative Big-Data-Toolbox Hadoop einfach erklärt
Das Big Data Tool Hadoop: Was ist es? Wie funktioniert es? Welche Tools aus dem Ökosystem können für was genutzt werden und wieso soll es eingesetzt werden?
Wenn ich heute über Data Science, Big Data oder Business Intelligence, kurz BI, spreche, so komme ich schnell zu Apache Hadoop. Es ist allgegenwärtig und wird in naher Zukunft viele IT-Pros betreffen. Dieser Artikel soll einen ersten Überblick über das Hadoop-Ökosystem geben. Was ist es? Wie funktioniert es? Welche Tools aus dem Ökosystem können für was genutzt werden und wieso soll es überhaupt eingesetzt werden?
Was ist Hadoop?
Hadoop ist ein in Java geschriebenes Open-Source-Framework, das die verteilte Verarbeitung von grossen Datensätzen über Cluster von Computern mit einfachen Programmiermodellen ermöglicht.
Wie funktioniert es?
Einfach gesagt: Eine spezifische Aufgabe der Datenbearbeitung und/oder -analyse kann auf verschiedene Computer in einem Cluster verteilt werden, ohne dass sich der Programmierer um die Art der Verteilung oder die Ausfallsicherheit kümmern muss. Der grosse Vorteil von Hadoop ist die Skalierbarkeit. Vor allem in Cloud-Umgebungen wie Microsoft Azure oder AWS, in denen ein Cluster innerhalb von Minuten erweitert werden kann, profitiert Hadoop, weil dadurch unendliche Ressourcen zur Datenanalyse geschaffen werden können.
Welche Tools aus dem Ökosystem können für was genutzt werden und wieso soll es überhaupt eingesetzt werden?
Das Hadoop Framework – das minimale Fundamt des Hadoop-Ökosystems – besteht grundsätzlich aus den folgenden vier Komponenten:
- Hadoop Common
Das sind die wichtigsten Java-Bibliotheken, die von den restlichen Hadoop-Modulen gebraucht werden, damit diese überhaupt funktionieren. - Hadoop YARN
YARN ist ein Framework, das für Job Scheduling und Cluster Resource Management benötigt wird. - Hadoop Distributed File System (HDFS)
HDFS ist der verteilte Speicher des Clusters. Er basiert auf dem Google File System (GFS) und stellt ein verteiltes Dateisystem zur Verfügung, das auf grossen Clustern (Tausenden von Computern) von kleinen Computern zuverlässig und fehlertolerant ausgeführt wird. HDFS arbeitet nach dem Master/Slave-Prinzip, wobei die Daten auf sogenannten Datenknoten auf dem Slave liegen. Der Master ist nur dafür verantwortlich, dass die nach der Aufgabe zu lesenden oder schreibenden Daten auf dem richtigen Datenknoten gefunden werden. - Hadoop MapReduce
MapReduce ist ein Software-Framework für das einfache Implementieren von Anwendungen, die grosse Mengen an Daten parallel auf grossen Clustern (Tausenden von Knoten) in einer zuverlässigen und fehlertoleranten Weise verarbeiten. MapReduce ist daher für das Verteilen und Wieder-Zusammenführen von den einzelnen Tasks verantwortlich.
MapReduce stellt den Rechenbereich dar, der mit Daten arbeitet, die im HDFS gespeichert sind. Somit können Skripte oder Tools ausgeführt werden, die das Hadoop Common verwenden. Das ist das Grundgerüst des Hadoop-Ökosystems, ohne die die restlichen Tools nicht funktionieren würden.
Es gibt inzwischen viele Tools im Hadoop-Ökosystem. Im Folgenden ein kurzer grafischer Überblick über den aktuellen Stand:
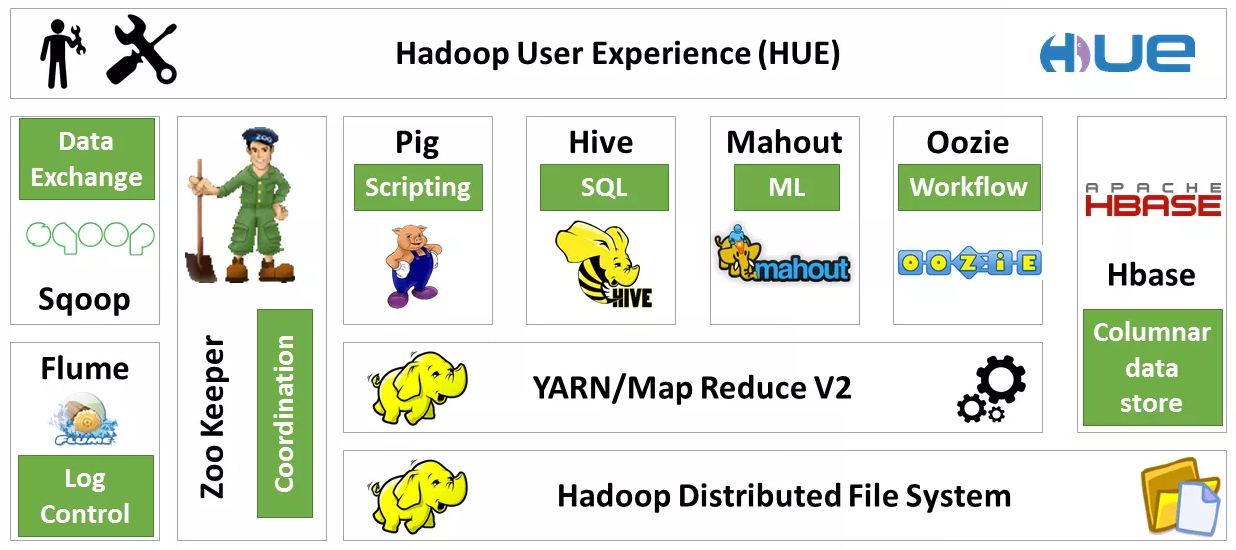
Figure 1: https://i1.wp.com/blog.leonelatencio.com/wp-content/uploads/2016/07/2_Scaling-up-with-Hadoop-and-Banyan-Hadoop-Family.png
Wie in der Grafik gut zu erkennen ist, stellt HDFS die Grundlage dar. MapReduce wird in nur einem Sonderfall nicht benötigt – und zwar dann, wenn Hbase zum Einsatz kommt. HBase ist im Vergleich mit den restlichen Tools kein Prozesstool, sondern eine Speicherart. Hbase ermöglicht es, Real-Time-Daten mit Millionen von Spalten und Billionen von Zeilen auf dem HDFS zu speichern.
Die restlichen Tools sind alles Prozessanwendungen, die auf MapReduce aufbauen. Folgend nun eine kurze Erklärung der wichtigsten Prozesstools und wo sie eingesetzt werden sollten:
Hive
Hive ist im Grunde genommen ein verteiltes Datawarehouse für die Verarbeitung von extrem grossen Datenmengen. Hive kann und soll wie SQL genutzt werden, da auch die Statements identisch sind.
Pig
Pig ist eine Skriptsprache, die es ermöglicht, komplizierte MapReduce-Transformationen durchzuführen. Die Befehle werden in der Sprache PigLatin geschrieben und anschliessend als MapReduce-Jobs ausgeführt. Häufigstes Anwendungsbeispiel sind ETL-Transformationen in HDFS.
Mahout
Mahout ist eine Machine-Learning-Bibliothek, die vor allem für Clusteranalysen oder Predictions eingesetzt wird.
Ein weiteres wichtiges Tool, das auf der Grafik nicht aufgezeigt wird, ist Spark. Spark ist eine Erweiterung des Hadoop-Ökosystems mit der Möglichkeit des Datastreamings und der Real-Time-Verarbeitung.
Wo soll Hadoop eingesetzt werden?
Abschliessend stellt sich noch die Frage, wann Hadoop eingesetzt werden soll.
An einem gewissen Punkt der Datenanalyse wird ein herkömmlicher Computer nicht mehr in der Lage sein, die Aufgaben innert einer vernünftigen Zeit abzuarbeiten. Hierbei gibt es keine feste Datengrösse, an der man sich orientieren kann, da nebst der reinen Grösse der Daten auch die Komplexität der Aufgabe eine Rolle spielt. Sobald dieser Punkt erreicht ist, wird man auf eine Clustercomputing-Lösung wechseln müssen, so wie es Hadoop eine – kostengünstige – ist.
Und noch eine kleine Anekdote zum Schluss: Der Name und das Logo sind zurückzuführen auf das Lieblingsstofftier des Kindes eines Entwicklers. Es war ein kleiner gelber Elefant namens Hadoop.
Big Data ist in aller Munde. Bringen Sie sich mit den Digicomp Kursen auf den neuesten Stand: Big Data ist in aller Munde. Bringen Sie sich mit den Digicomp Kursen auf den neuesten Stand:
Big-Data-Kurse bei Digicomp