Sichern von Veeam-Backups auf Cloudspeicher (AWS) – Teil 1 von 3
Rinon Belegu zeigt in diesem ersten Beitrag (1 von 3) die Anforderungen und die ersten Schritte auf, mit der man Backups mit Veeam auf Cloud-Speicher ablegen kann.
Die Anfragen von Kunden, die Backups mit Veeam auf Cloud-Speicher ablegen möchten, häufen sich. Rinon Belegu zeigt in diesem Beitrag die Anforderungen und die ersten Schritte zur Erreichung dieses Ziels auf.
Veeam ist eine Backup-Software, die ihre Wurzeln im Backup von virtuellen Infrastrukturen hat, jedoch immer mehr Features auch für die physische Welt mit sich bringt. Die Software speichert die Daten auf sogenannten Backup-Repositories. Diese können in verschiedensten Formen zur Verfügung gestellt werden. Weiter ist es möglich, auf Bändern eine Sicherung abzulegen.
Die von mir aus gesehen beste Lösung ist es, auf einen Veeam-Cloud-Connect-Speicher zu sichern. Dazu wendet man sich an einen der Veeam Cloud Connect Partner. Diese bieten einen angepassten Dienst, der sich homogen in die Veeam-Welt einfügt. Man fügt das Cloud Connect Repository hinzu und kann es wie ein «normales» Veeam-Repository ansteuern.
Einige Kunden haben jedoch das Bedürfnis, die Sicherung bei ihrem bestehenden Cloud-Anbieter wie AWS durchzuführen. Die Voraussetzung dafür ist der Einsatz des AWS Storage Gateways. Dieser kann in AWS selbst oder lokal gehostet werden. In diesem Beitrag zeige ich, wie die Lösung lokal erstellt wird.
Der AWS Storage Gateway kann in verschiedenen Modi betrieben werden. In diesem Beitrag, konzentrieren wir uns auf die Verwendung als Virtual Tape Libarary (VTL). Wir emulieren also ein Bandlaufwerk.
Architekturübersicht AWS Storage Gateway – Tape
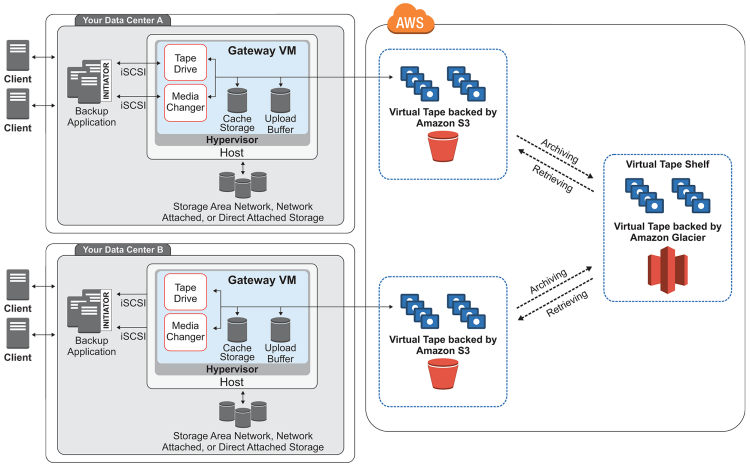
Der Tape-Gateway wird als VM lokal oder auf AWS deployed. Er kann über iSCSI angesprochen werden. Im unseren Fall werden wir den Gateway-Server lokal auf einer VMware-Umgebung laufen lassen. Das wichtigste bei dem Sizing des Tape-Gaways sind die Cache-Storage-Grösse und die Upload-Buffer-Grösse. Generell ist hier das empfohlene Minimum 150 GiB. In unserem Lab-Setup werden wir die Grösse reduzieren.
Upload Buffer
Der Upload Buffer dient als Staging-Bereich für Daten, die auf AWS hochgeladen werden. Mit der folgenden Formel haben wir eine Faustregel zur Errechnung der Grösse.

Ich empfehle das Monitoring des Buffers, um ausfindig zu machen, ob der Buffer über die richtige Grösse verfügt.
Die Metriken, die wir für den Tape-Gateway beachten sollten, sind folgende:
- UploadBufferFree (Bytes): Freier Speicherplatz im Upload Buffer des Gateways
- UploadBuferPercentUsed (Prozent): Prozentuale Auslastung des Upload Buffers
- UploadBufferUsed (Bytes): Verwendeter Speicherplatz im Upload Buffer
Das Zeitintervall für diese Metriken beträgt 5 Minuten. Basierend auf den CloudWatch empfehle ich, einen Alarm zu generieren, falls die Auslastung sehr hoch ist, z.B. 80%, oder der freie Speicherplatz sehr tief. So kann man frühzeitig auf eventuell sich verlagernde Anforderungen reagieren.
Cache Storage

Im Cache Storage befinden sich Daten, die ich lokal «schnell» verfügbar haben will. Dass heisst, im Falle eines Restores wird zuerst der Cache Storage angefragt, bevor ein Request auf die AWS-Infrastruktur abgesetzt wird. Für die Grösse des Cache Storage sollte man 1.1 x (Upload Buffer) rechnen. Ist der Cache gefüllt, wird der Write der Applikation angehalten.
Vorgehen
Zuerst melde ich mich an der AWS Console an und suche nach Storage Gateway.
Auf der Welcome Page wählt man «Get started».
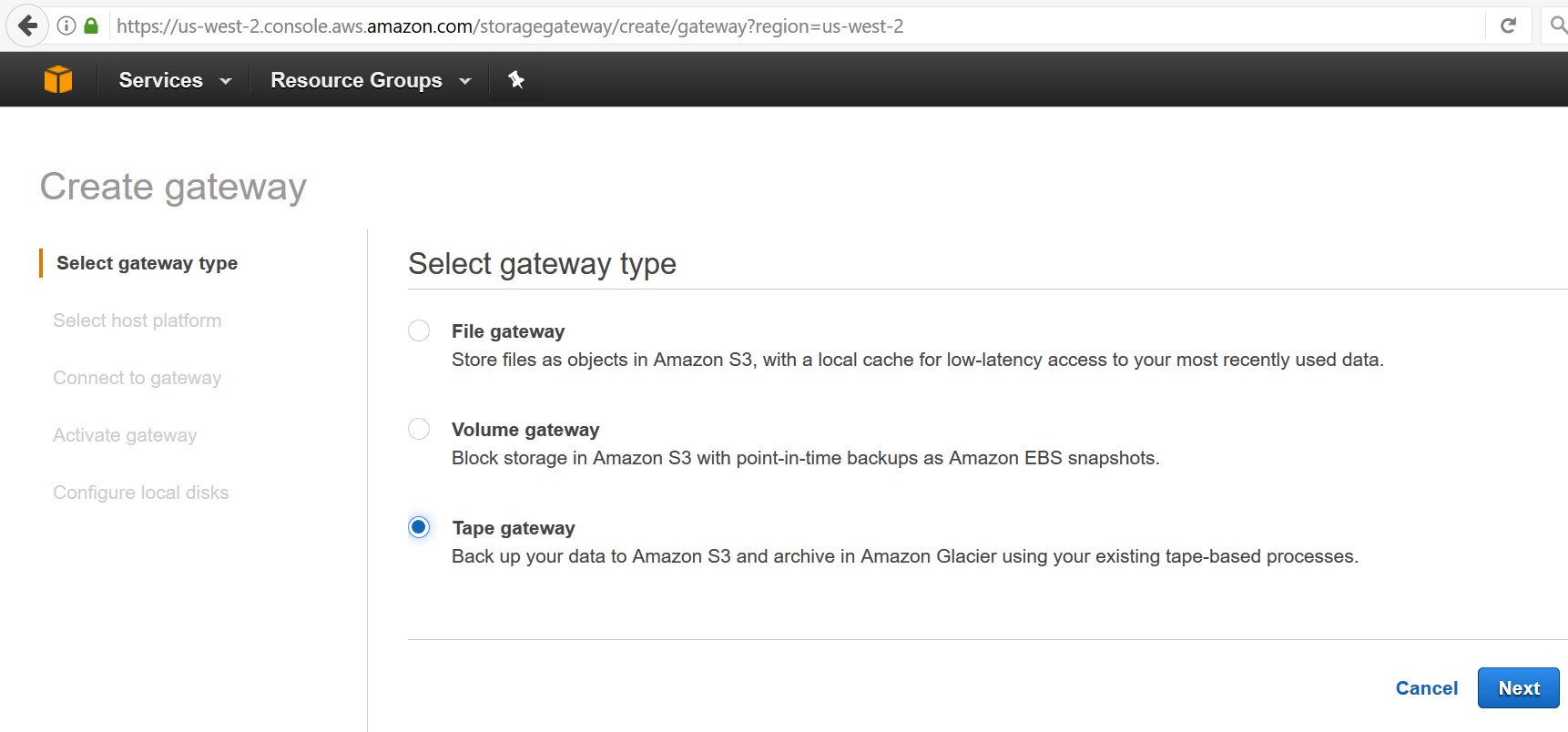
Nun definiere ich als Gateway Typ «Tape gateway» und bestätige mit «Next».
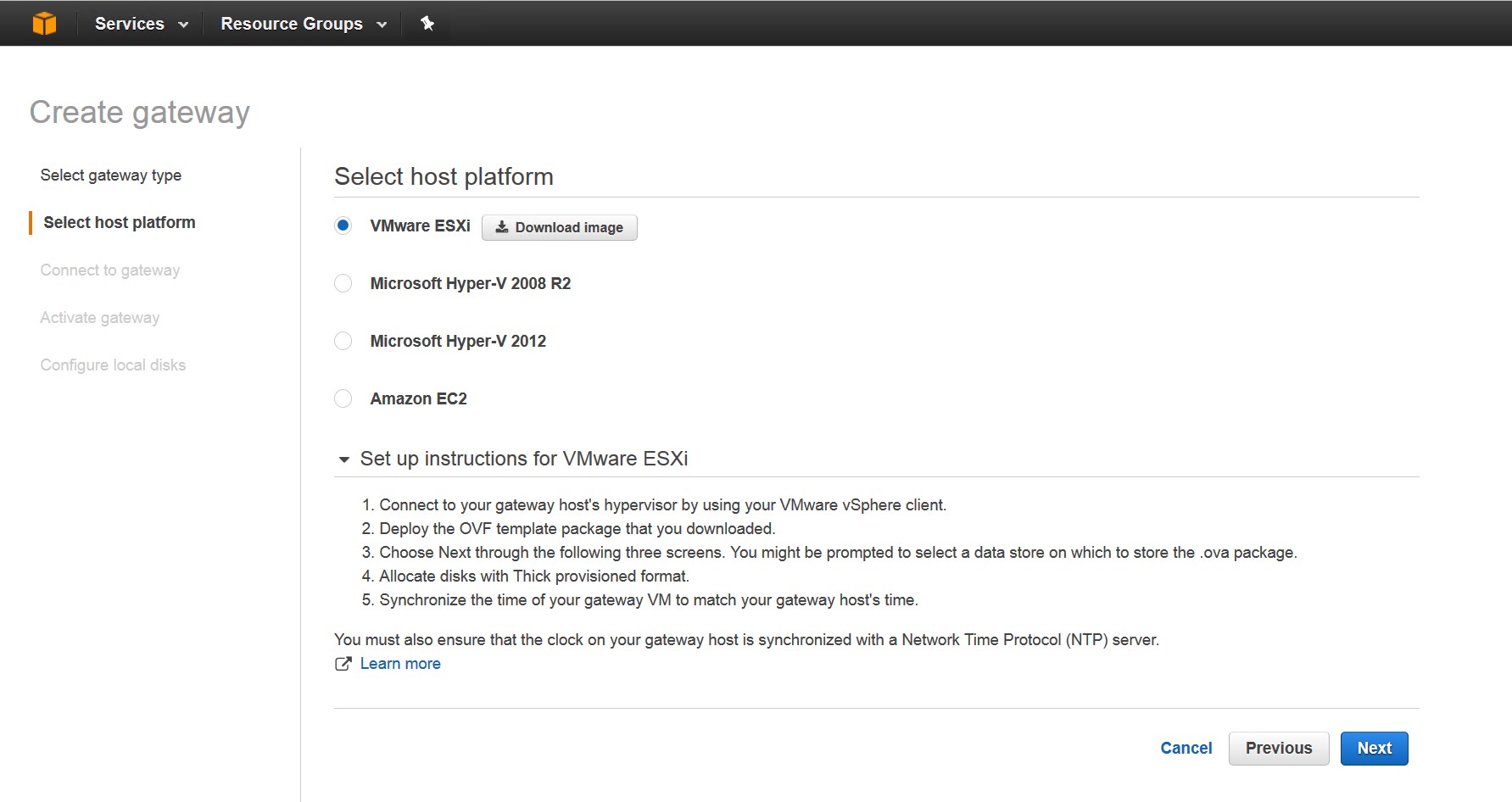
Als Plattform definiere ich «VMware ESXi» und lade das Image.

Im Zip-Paket ist ein «OVA»-Image, das man für VMware verwenden kann und das einige Informationen enthält.
Ich verbinde mich z.B. mit dem Legacy vSphere Client auf einen ESXi Server.

Nun gehe ich auf «File > Deploy OVF Template…»

Ich wähle das vorher geladene «OVA»-Image.
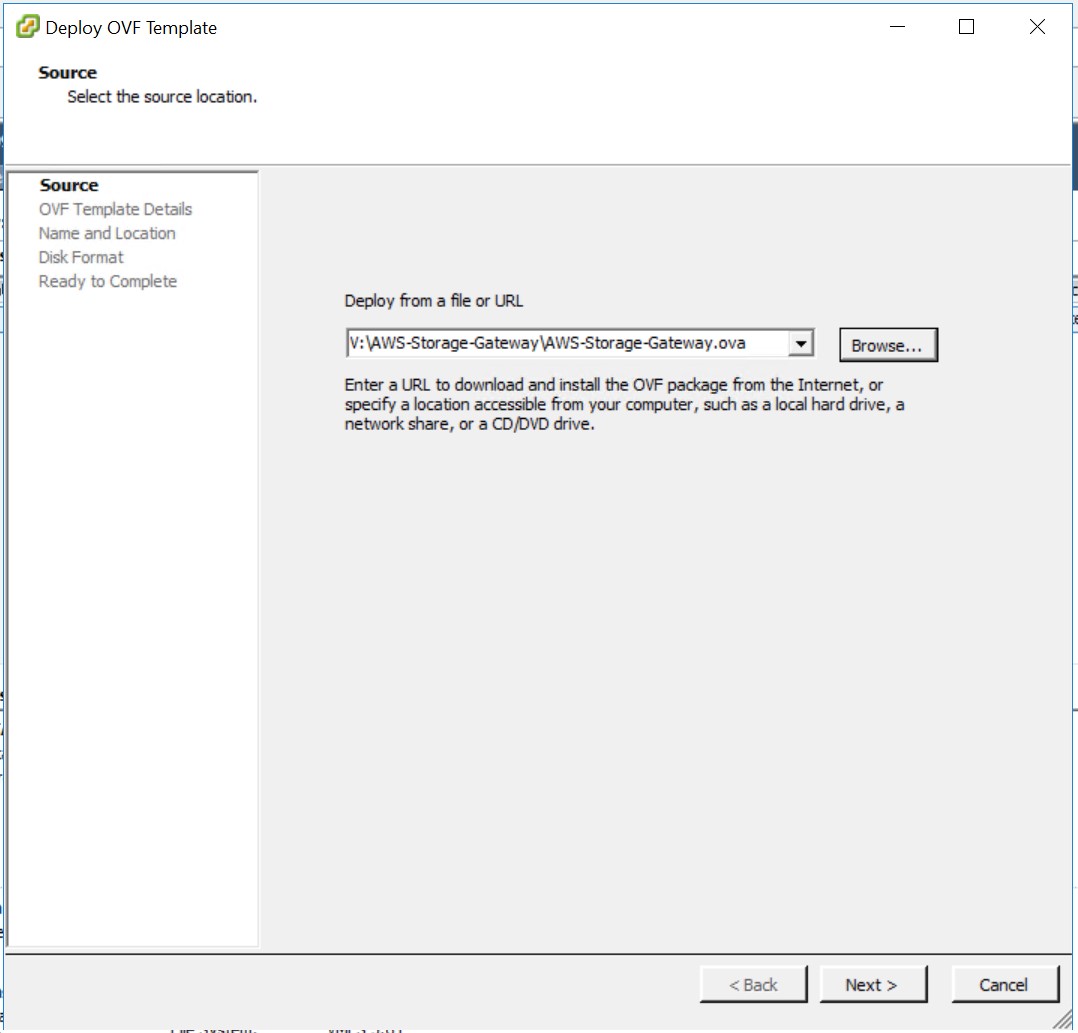
Nun bestätige ich mit «Next».
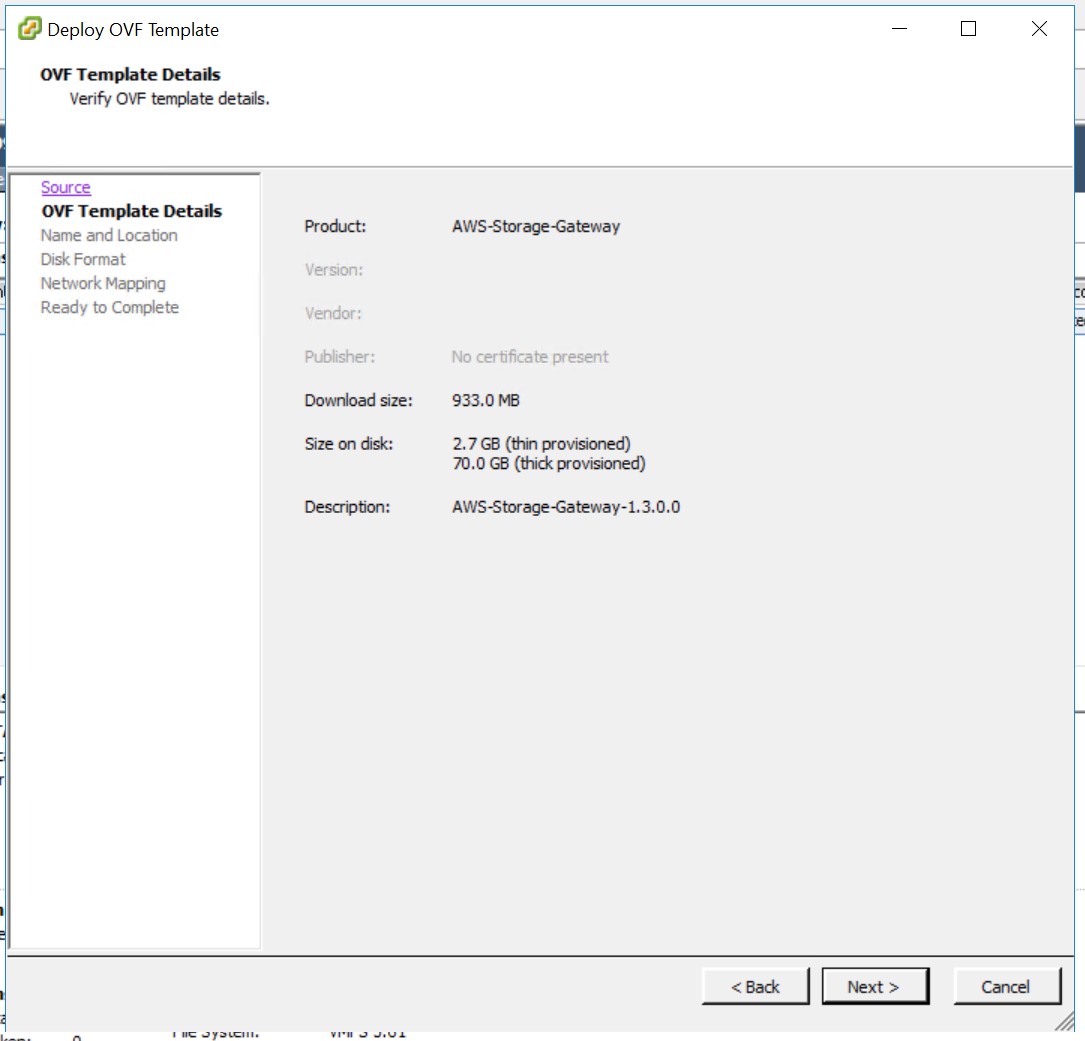
Bei den «Template Details» bestätige ich mit «Next».
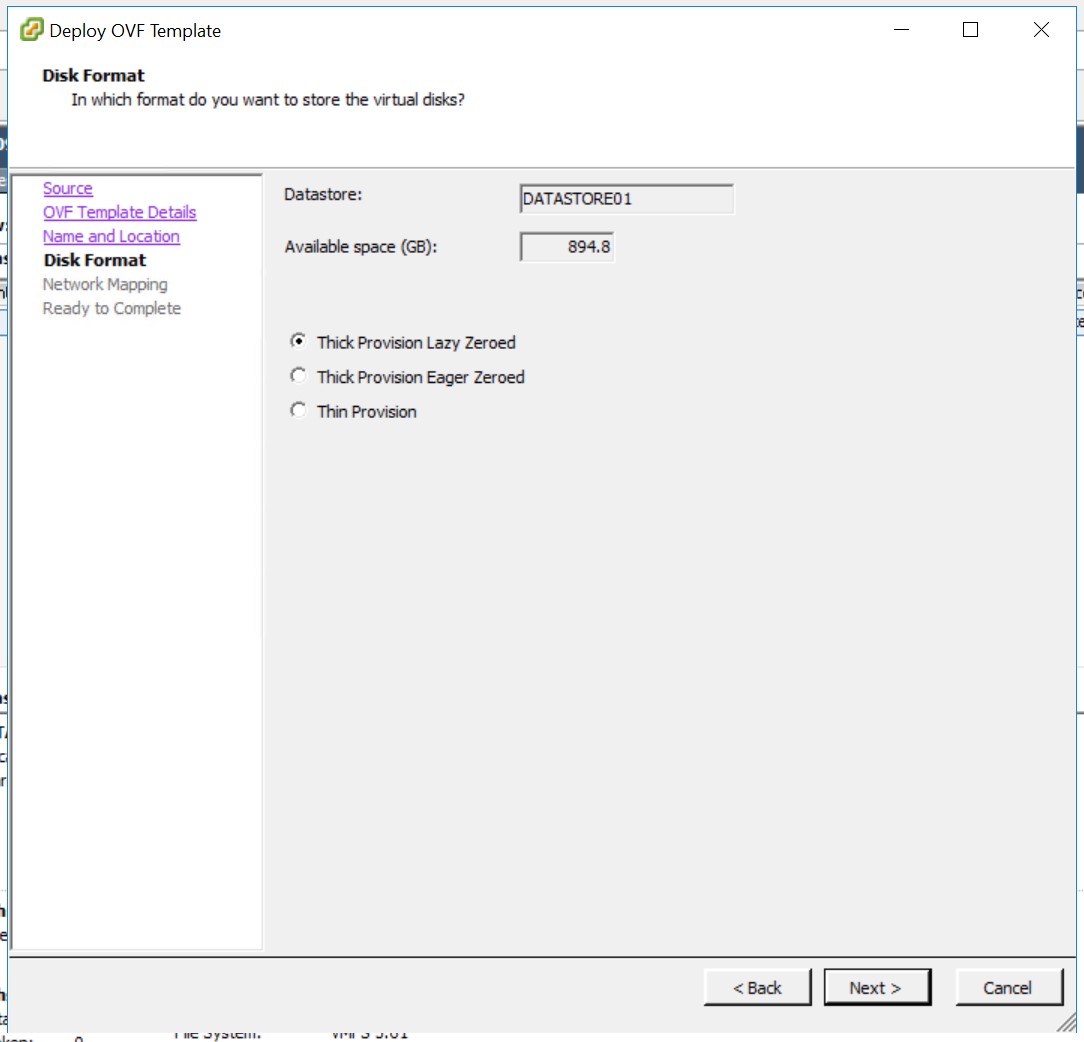
Ich halte mich an die Vorgaben von AWS, wähle «Thick» Disk aus und bestätigen mit «Next».
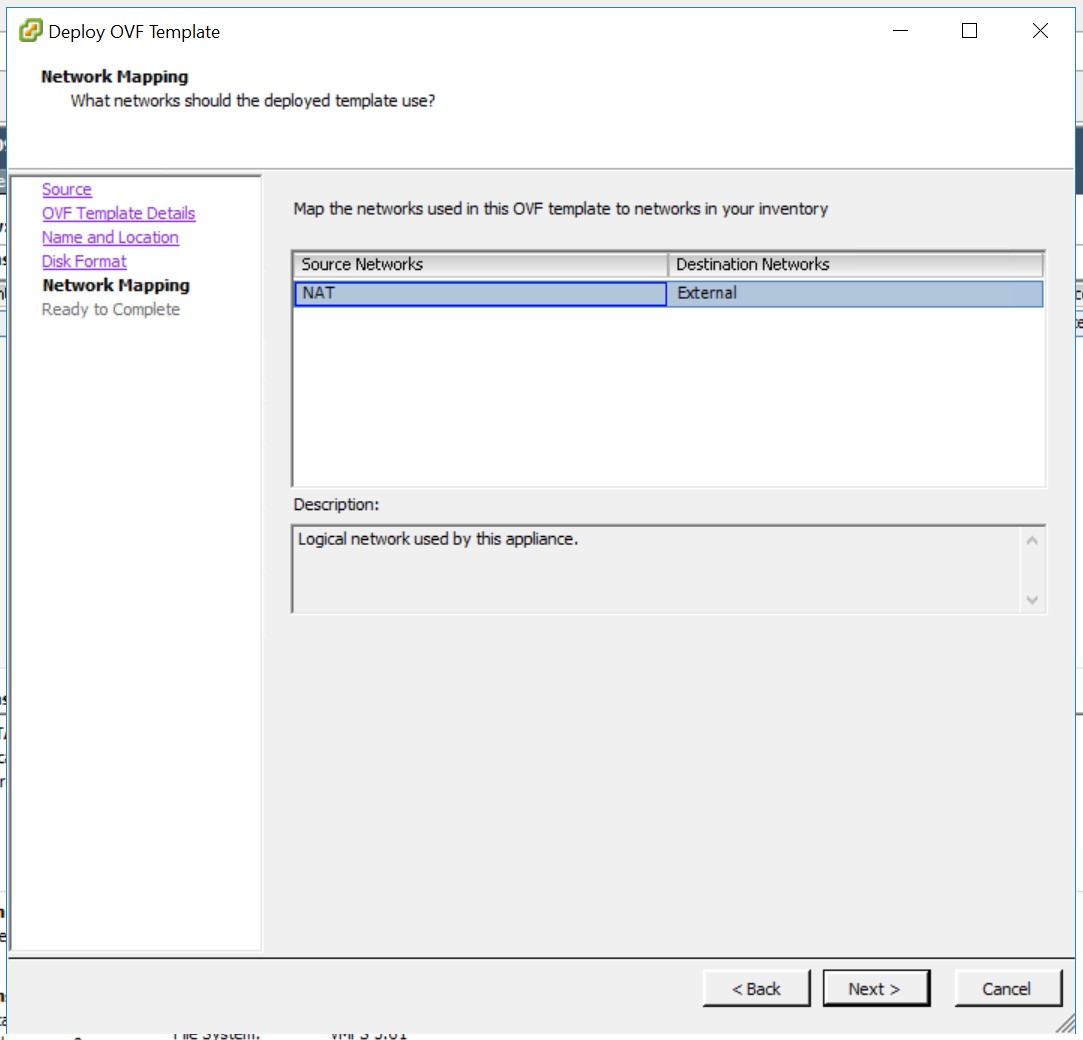
Ich wähle ein Netzwerk aus, über das ich nachher die Synchronisation durchführen kann und bestätige mit «Next».
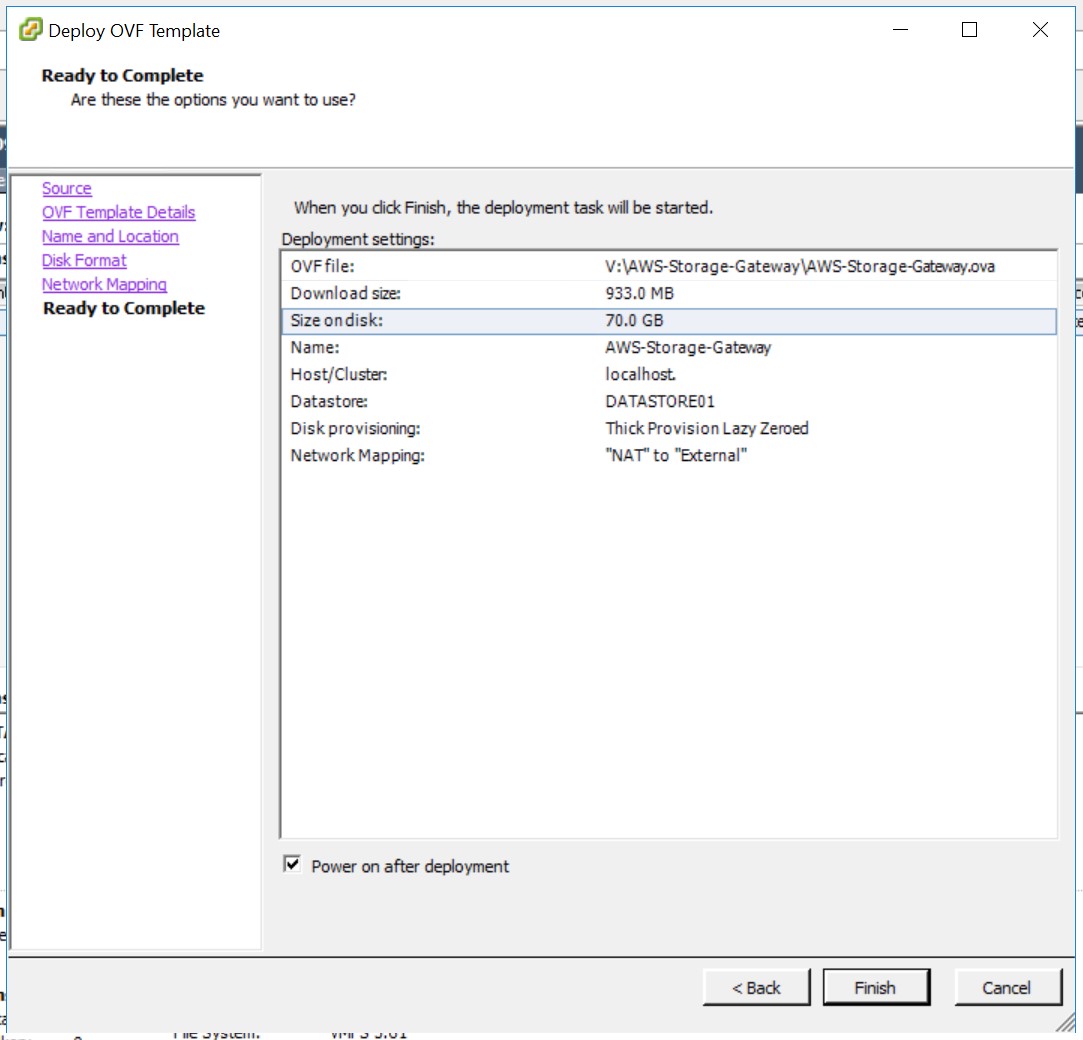
Die Zusammenfassung bestätige ich mit «Finish». Falls gewünscht, kann die VM direkt gestartet werden.